Choosing an RPC Proxy: aetherlay vs dshackle
 Credits: Santiago Botto
Credits: Santiago BottoChoosing an RPC Proxy: aetherlay vs dshackle
Full disclosure: I created and currently maintain aetherlay. Still, you’ll find that I’m fair when I compare it to dshackle. Stick until the end to find out!
TL;DR
-
Goal: compare aetherlay and dshackle as RPC proxies on Kubernetes using Grafana’s k6 load tests.
-
Setup: single-node minikube running locally on a MacBook Pro (M2), k6 local execution with cloud UI, equal total CPU and RAM budgets per stack.
-
Headline: dshackle is faster on successful requests at higher load but has issues staying online, aetherlay is more reliable across tests.
-
When to choose aetherlay? You want predictable failover, low error rates, and a Kubernetes-first approach to your service.
-
When to choose dshackle? You want lower latency and can invest time and resources into tuning the service to keep it stable.
Intro
In the growing Web3 ecosystem, reliable access to blockchain nodes is critical. Enterprises and infrastructure providers often face a choice between using third-party RPC endpoint providers, such as Alchemy or dRPC, or spinning up their own nodes. Developers and small teams, on the other hand, usually lack the budget to run their own nodes and thus can only turn to third-party providers.
In all cases, when it comes to using a third-party provider, teams will usually prefer to use more than one of them for redundancy, but who’s got the time to deal with the automations required to do that?
The good news is that there’s already tools that help solve this problem! Two such tools are aetherlay and dshackle. While both serve similar purposes, they differ in design philosophy, feature set, and practical outcomes.
This post explores their key differences, strengths and trade-offs, backed by benchmarks that we ran, which reveal critical performance considerations.
What is aetherlay?
Aetherlay is a lightweight RPC proxy and load balancer focused on quick setup and predictable behavior:
-
Quick Setup: Minimal configuration, intuitive defaults.
-
Load Balancing: Distributes requests across multiple nodes.
-
Failover: Automatically switches to a healthy node when one becomes unresponsive.
-
Metrics: Exposes performance data for monitoring and optimization.
-
Fully customizable health checks: Users can choose how and when to run health checks, which is especially useful when dealing with third-party endpoints that charge per request.
Aetherlay is ideal for teams that want reliability without the overhead of managing complex infrastructure. It was built specifically to target some weak points that we found while working with dshackle, like wasting third-party RPC credits on excessive health checks that you can’t customize (dshackle has flags to do it but they don’t work).
What is dshackle?
Dshackle, originally from EmeraldPay and now largely maintained in a fork by dRPC, is a configurable node proxy and aggregator. It’s aimed at teams that manage their own RPC nodes, and some of its key features are:
-
Routing Rules: Supports rules to direct specific methods (e.g.,
eth_call,eth_getLogs) to particular nodes. -
Response Validation: Can discard or sanitize invalid node responses.
-
Prometheus Metrics: Exposes detailed per-node and per-method metrics for monitoring.
-
Configurable Policies: Provides options for failover, throttling, and request distribution.
-
Of course, it also has essentially the same Failover and Load Balancing capabilities as aetherlay, although the implementation differs.
Dshackle offers more configuration options than aetherlay (except when it comes to health checks), but those extra features come with setup complexity and, as benchmarks show, some performance overhead.
Benchmark setup
Both aetherlay and dshackle were deployed to a single-node minikube cluster running on a local MacBook Pro (M2).
Grafana’s k6 was the tool chosen to run these tests since it’s quite convenient and provides great metrics. We ran using local execution with cloud storage (k6 cloud run --local-execution script.js) so that we could get the charts from the web UI.
Resources assigned to each service:
-
Dshackle:
- 1 replica, 1 CPU and 1GiB memory.
-
Aetherlay:
- Load Balancer: 3 replicas, 300m CPU and 300MiB memory per replica.
- Health Checker: 1 replica, 50m CPU and 50MiB memory.
- Valkey: 1 replica, 50m CPU and 50MiB memory.
(This gives us 1 CPU and 1GiB of RAM for the whole stack).
Additional considerations:
-
Request types sent by the k6 test script were:
eth_blockNumber,eth_getBalanceandeth_getBlockByNumber. -
The same request payloads were used for testing both services, with gzip off and no client retries.
-
Both services had only two RPC endpoints set as primary endpoints, which are two of the self-hosted RPC nodes that we deployed with TechOps; one “geth”, one “reth”.
Fairness and limits
-
Exact versions, flags and configs are published here so that anyone can rerun the tests.
-
Aetherlay runs multiple replicas of its Load Balancer by design. The same amount of resources were assigned to each service and neither had autoscaling enabled. Dshackle runs as a single pod in these tests because that’s how it was built.
-
Failure definition: k6 counted timeouts or errors as failures. Latency percentiles include only successful responses so we can compare speed on good responses while still tracking failure rates separately.
-
Retries: client retries were off. That improves test clarity. We understand that it may understate real-world resilience for setups that do client-side retries but that wasn’t the point of these tests, only the services themselves are being put to the test, not client-side implementations.
Results
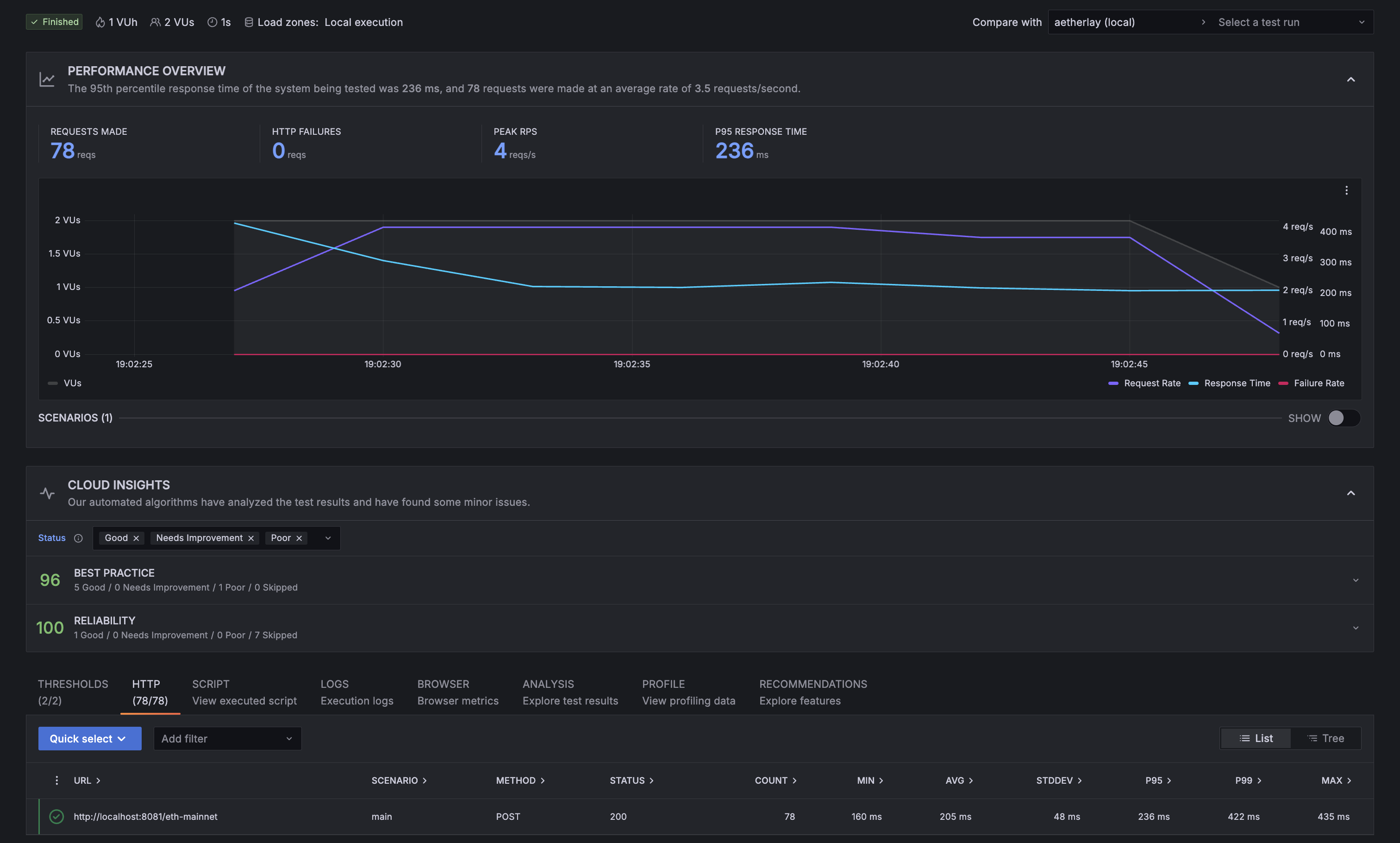
2 VUs, 21 seconds
With only 2 concurrent Virtual Users running for just 21 seconds, requests were processed blazingly fast by aetherlay (205ms on average):
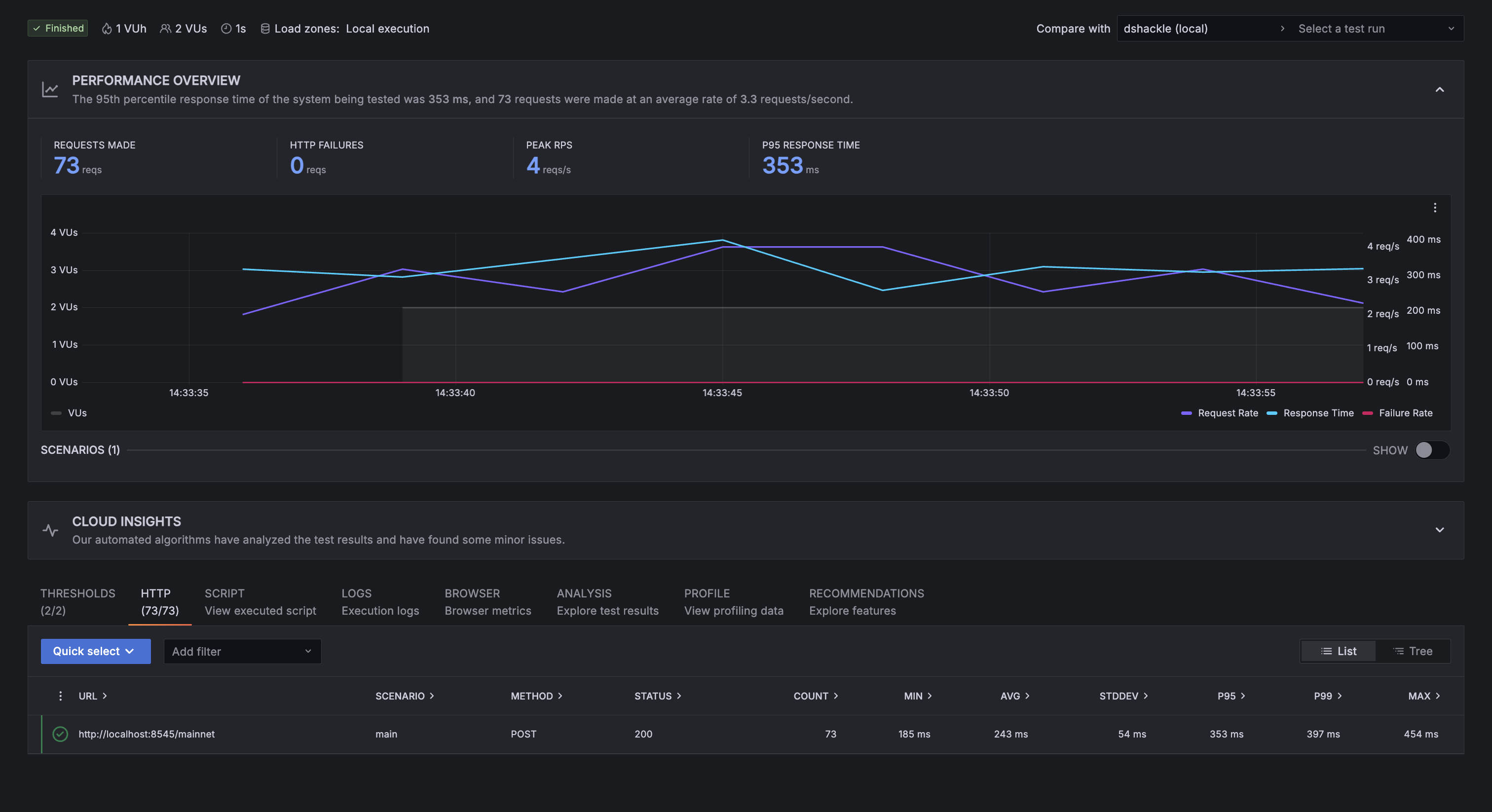
Dshackle’s performance was quite similar for this short test, although a bit slower:
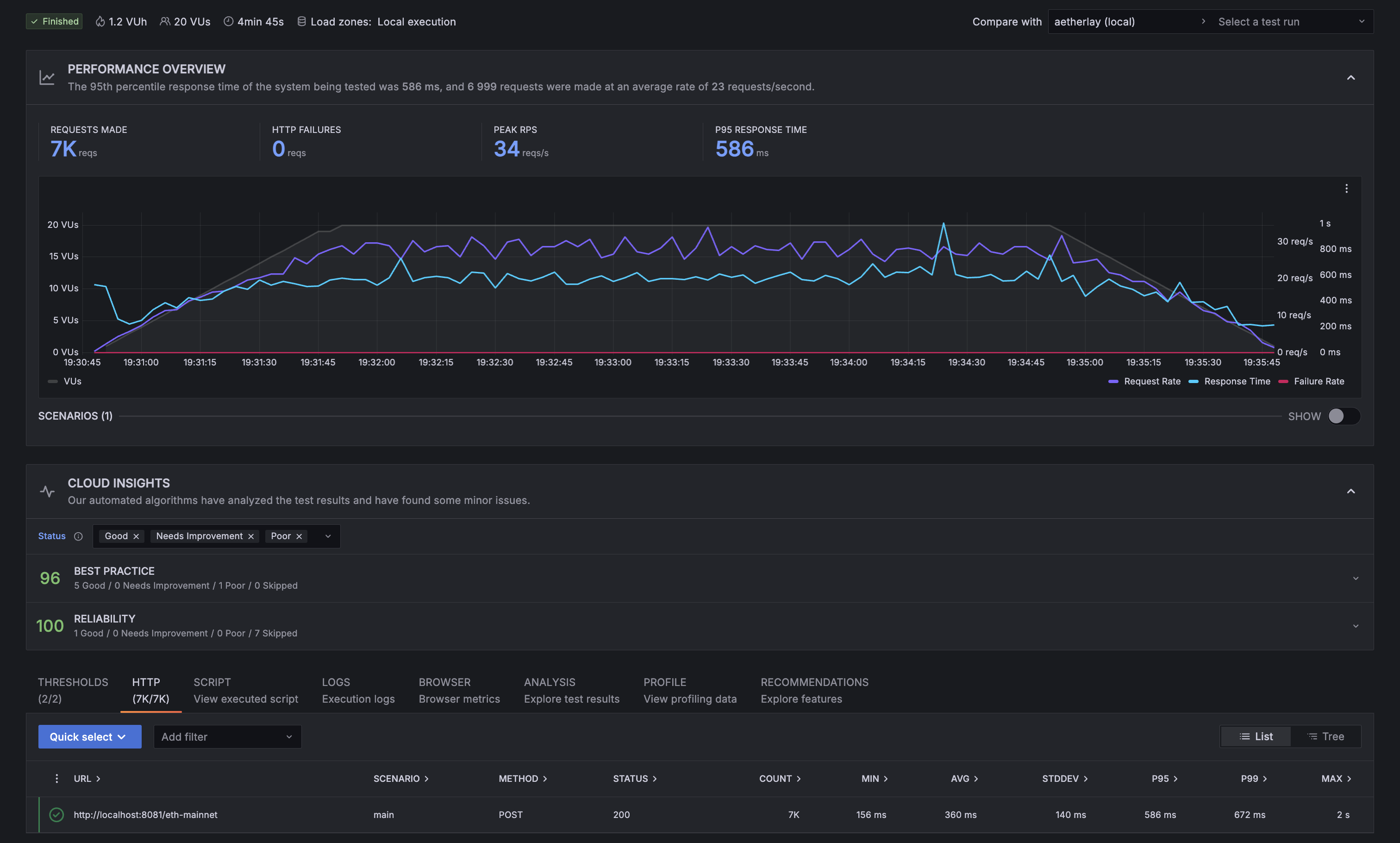
20 VUs, 5 minutes
With 20 concurrent users running for about 5 minutes, requests took longer to be processed by aetherlay but they were still processed quite quickly, averaging 360ms per request:
In comparison, dshackle struggled quite a lot. It was only able to handle requests for the first minute, while the amount of concurrent users was still getting up to 20. Then, while serving 20 concurrent users, it only lasted a few seconds before completely crashing, as you can see in the chart below:
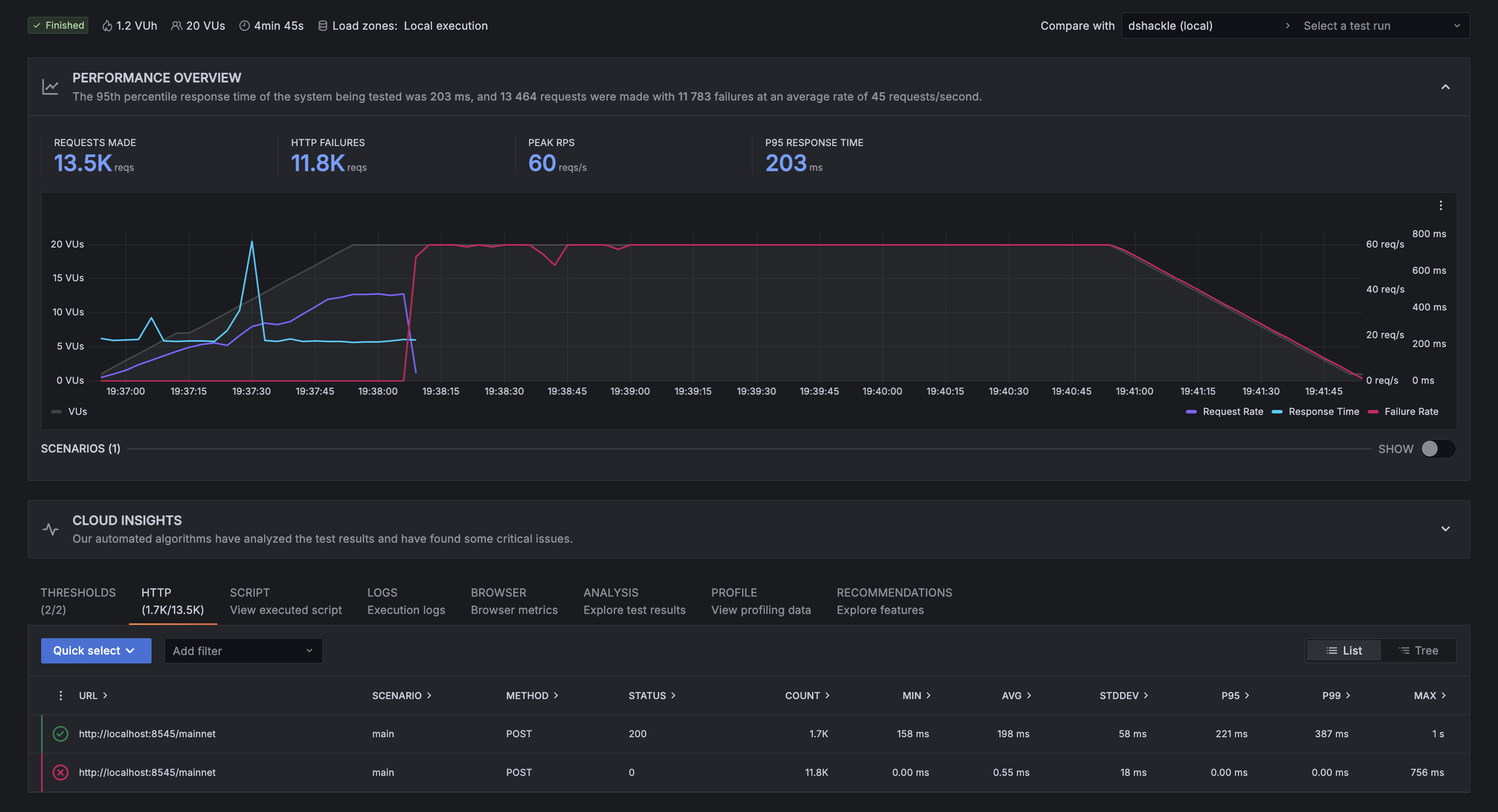
It’s true that the average response time was lower than aetherlay for the time it was able to serve requests, but request rate was still the same for both services. Given the great disadvantage of completely crashing under just 20 concurrent users, we consider that a minor improvement in response time is completely irrelevant. We’d rather have a service working with average performance than a service with better performance that works only for a while.
200 VUs, 5 minutes
With 200 concurrent users, aetherlay’s performance started to take a hit. Failure rate was still almost 0, but the time it took to handle each request significantly increased, averaging 2 seconds. In a real-life scenario, this performance degradation would’ve only lasted a short amount of time since autoscaling via HPA would’ve kicked in and created more pods for aetherlay to be able to handle the increased load:
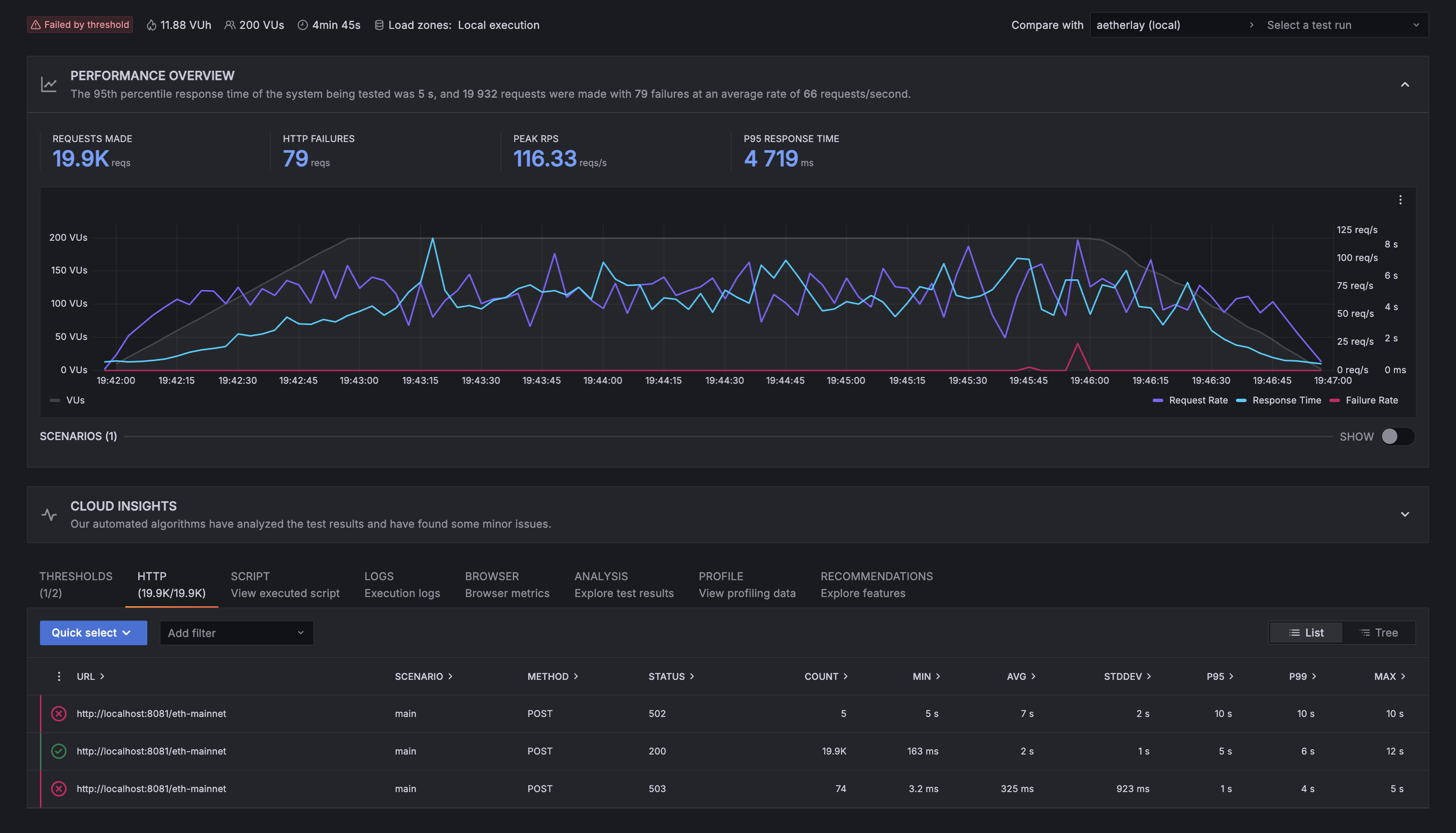
In comparison, dshackle struggled a lot to stay online, it kept crashing every other minute. When it did run, it averaged 679ms per successful request and, even staying online for less time than aetherlay, it still managed to serve more requests. So, in this test, dshackle showed a better performance but only when it managed to stay online:
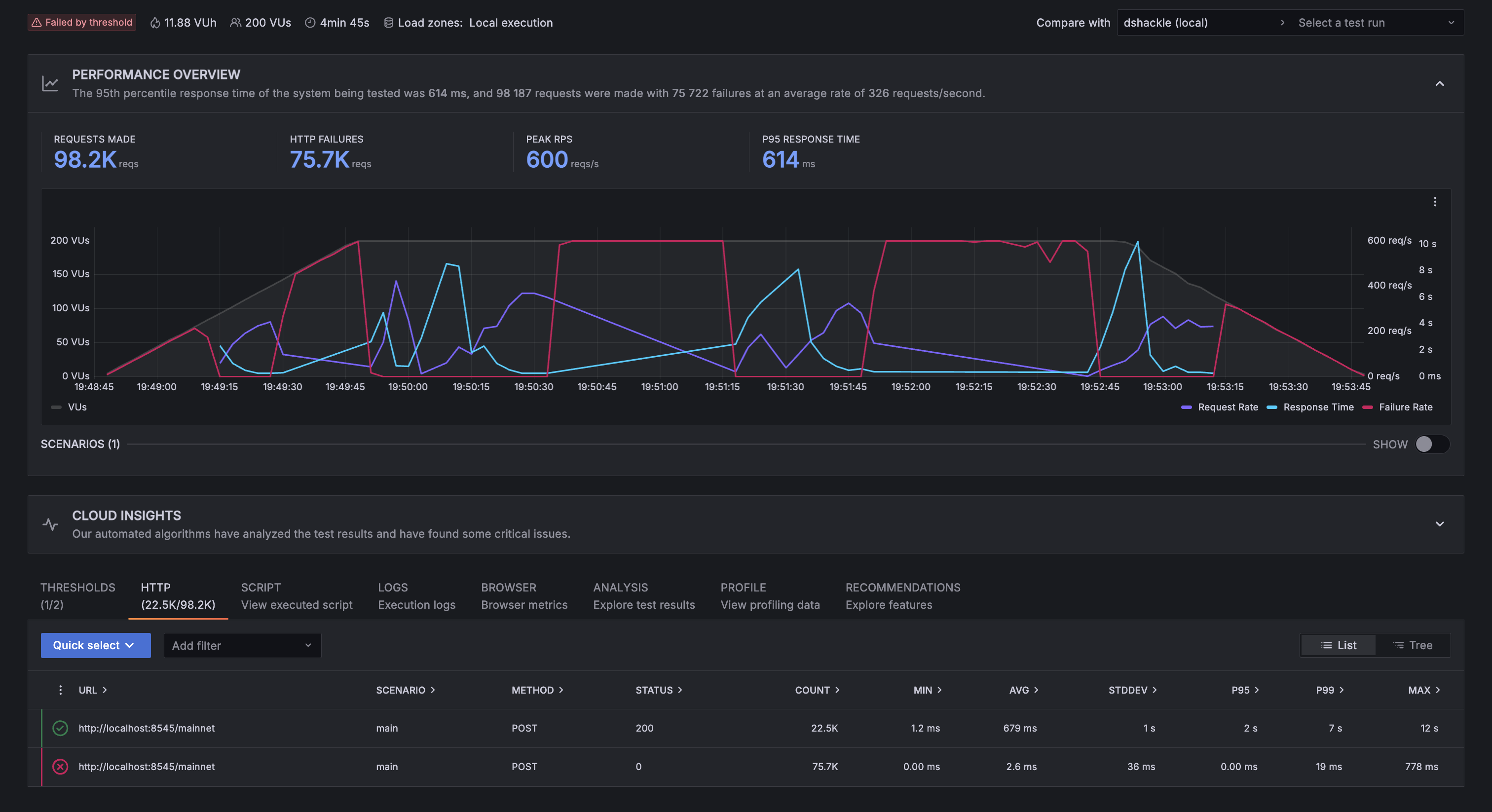
The important thing to consider here is that, in order for Dhsackle to become responsive again after crashing, it had to be restarted manually, and it took about a minute for it to start (this is the standard delay we saw when starting dshackle, it wasn’t specific to this test). In the screenshot above, you can see spikes in errors (the red line) that correspond to each crash and those spikes last for about 1 minute on average; sometimes less, sometimes more.
Having said this, we consider that a greater performance means nothing in this case since staying on top of a service 24/7 in order to keep it running is not really sustainable or convenient for anyone. We’ll take reliability over performance any day of the week.
20 VUs, 3 minutes (winding down)
Taking it back down to 20 concurrent users, the performance of aetherlay went back to normal:
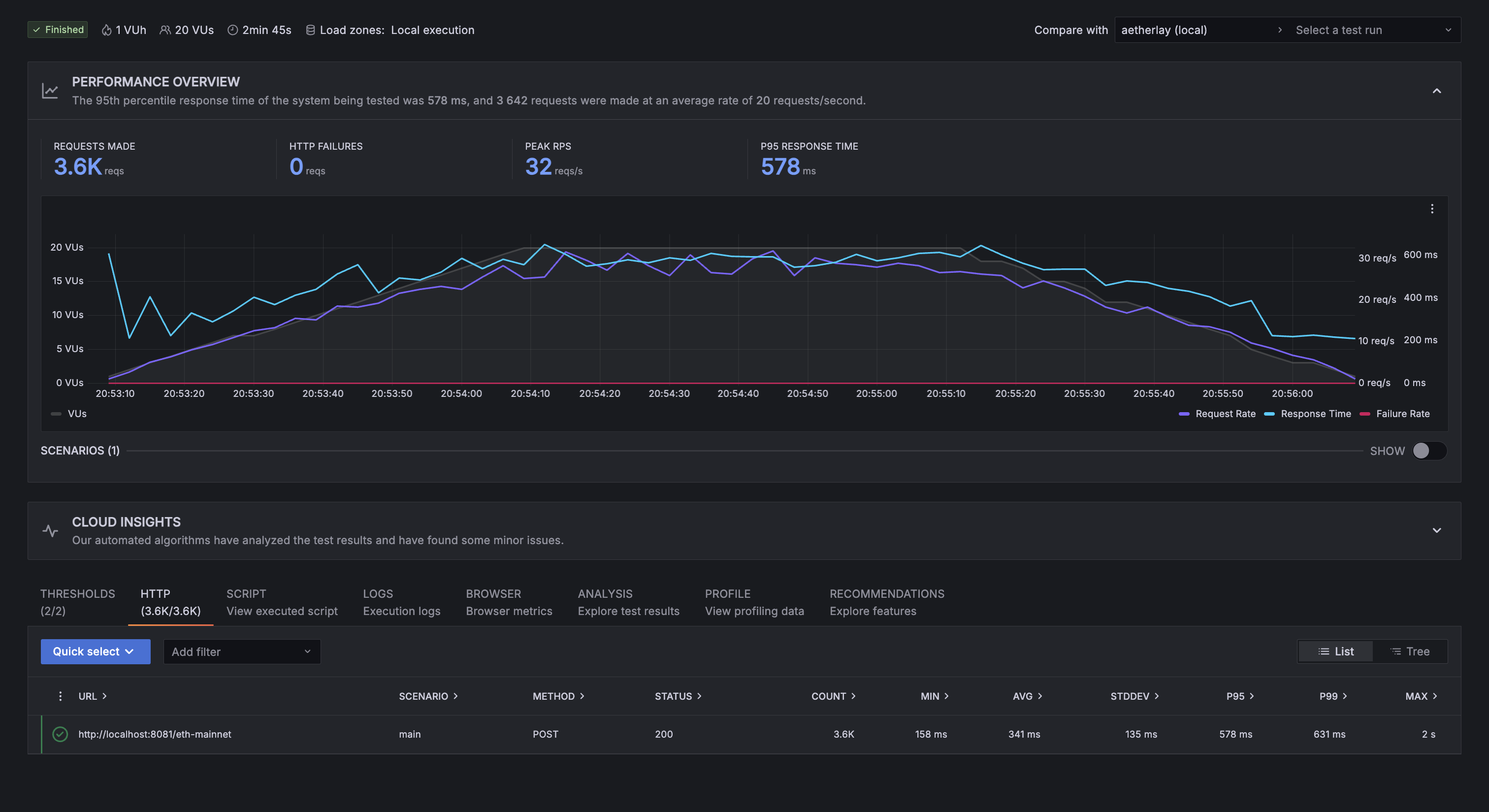
In comparison, dshackle completely crashed after the previous tests, so the results show a 100% failure rate:
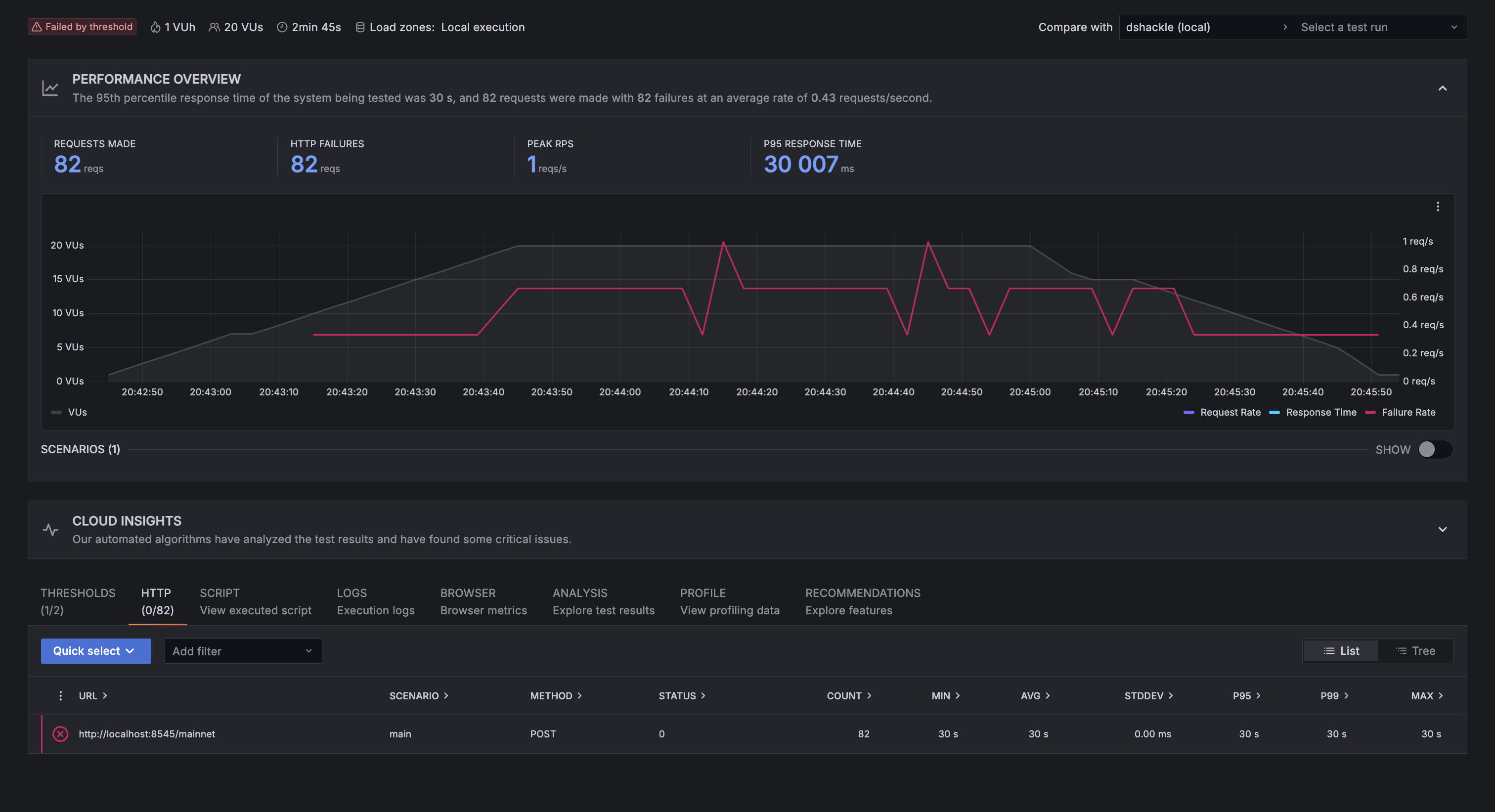
The thing to note here is that dshackle wasn’t failing like you’d expect a pod to fail, which would cause it to be replaced by the cluster, it just stayed in this failed state until we manually did something about it, like deleting the pod for minikube to create a new one to replace it.
Summary:
-
2 VUs, 21 seconds: Both tools respond quickly and cleanly at very low load, no meaningful difference for steady light traffic.
-
20 VUs, 5 minutes: Dshackle’s successful responses are faster, yet it repeatedly crashes once all 20 VUs are running. In our runs, that yielded roughly 62.5% failures. Aetherlay stays up with slightly higher latency and 0% failures.
-
200 VUs, 5 minutes: Dshackle remains faster on successful responses, yet it struggles to stay online and requires manual restarts to recover, with a 1-minute cold start. Aetherlay degrades to higher latency at this load yet keeps the error rate near zero. In a production cluster, an HPA would cut that latency spike by adding replicas, which would become available almost instantly.
-
20 VUs, 3 minutes (winding down): As if nothing had happened, aetherlay shows the same performance as previously, while dshackle stayed offline and was unable to recover itself.
In numbers:
| Stage | Tool | Runs | Successful requests | Successful RPS (avg) | p50 | p95 | p99 | Failure rate |
|---|---|---|---|---|---|---|---|---|
| 2 VUs, 21s | aetherlay | 1 | 78 | 3.71 | 198 ms | 251 ms | 265 ms | 0.00% |
| 2 VUs, 21s | dshackle | 1 | 73 | 3.48 | 230 ms | 322 ms | 347 ms | 0.00% |
| 20 VUs, 5m | aetherlay | 3 | 7269 | 23.33 | 346 ms | 530 ms | 576 ms | 0.00% |
| 20 VUs, 5m | dshackle | 3 | 2389 | 28.06 | 215 ms | 352 ms | 426 ms | ~62.5% |
| 200 VUs, 5m | aetherlay | 3 | 43435 | 66.09 | 1.74 s | 3.52 s | 4.32 s | 0.15% |
| 200 VUs, 5m | dshackle | 3 | 36027 | 111.98 | 500 ms | 1.27 s | 1.74 s | 74.33% |
Before we receive hate due to our testing approach...
It’s true we did not spend time working on JVM heap, GC, thread pools or specialized route rules in order to try to stop dshackle from crashing. Also, running multiple dshackle replicas should be possible and might improve stability, but that was outside the scope of this test.
The idea here was to test two out-of-the-box services and how they behave in a typical Kubernetes environment. We don’t think it’s practical to expect users to get deep into improving a service they don’t own just to keep it from failing under load, so we didn’t test for that.
We always assume that, if a user has a bad experience with a service, they’ll just move on to an alternative, which is exactly what we wanted to do back when we had issues with dshackle but, in this case, one of us had to build it from scratch 😅
Conclusions
If you value reliability over performance, pick aetherlay:
-
Keeps serving traffic under high loads with very low error rates.
-
Out-of-the-box scalability.
-
Low resource usage.
If you want lower latency and you can can invest time and resources into tuning the service to keep it stable, consider dshackle:
-
Delivers faster successful responses at higher loads.
-
Already has built-in support for routing rules to send specific methods to specific nodes.
Just remember to keep in mind that it requires work to avoid crashes and to recover without manual action. Also, its 1-minute startup time is non-trivial when recovering from issues.
Reproduce and challenge our results!
We have published a repo with:
-
Full configs for both services.
-
Steps to run the minikube environment.
-
k6 scripts to generate the traffic and test each service.
We invite everyone to re-run these tests and share the results with us. It’ll be nice to get more people trying out aetherlay and helping us find issues with it so that, together, we can continue to shape aetherlay into a great tool for the whole Web3 community 🚀

